- Published on
ClickHouse 技术解析:高性能列式数据库的应用与实践
- Authors

- Name
- Liant
基础介绍
介绍
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
适用场景
- 商业智能
- 电信行业数据存储统计
- 新浪微博用户行为记录分析
- 电子商务用户分析
- 金融等领域
不适用的场景
- 不支持事务
- 不擅长根据主键按行粒度进行查询(虽然支持)
- 不擅长按行删除数据(虽然支持)
- 不擅长按行更新数据(虽然支持)
100million条数据量下,ClickHouse的单表聚合查询性能非常高,是Greenplum(x2)集群的16倍,是PostgreSQL的10倍,是Mysql的833倍。
安装
1.amd64架构上,需要检查sse4_2指令集
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
2.deb包安装
$ sudo apt-get install -y apt-transport-https ca-certificates dirmngr
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 8919F6BD2B48D754
$ echo "deb https://packages.clickhouse.com/deb stable main" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
$ sudo apt-get update
$ sudo apt-get install -y clickhouse-server clickhouse-client
$ sudo service clickhouse-server start
# or "clickhouse-client --password" if you've set up a password.
$ clickhouse-client
使用
创建表
-- clickhouse-client 执行
CREATE TABLE uk_price_paid
(
price UInt32,
date Date,
postcode1 LowCardinality(String),
postcode2 LowCardinality(String),
type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),
is_new UInt8,
duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),
addr1 String,
addr2 String,
street LowCardinality(String),
locality LowCardinality(String),
town LowCardinality(String),
district LowCardinality(String),
county LowCardinality(String)
)
ENGINE = MergeTree
ORDER BY (postcode1, postcode2, addr1, addr2);
创建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
一般CREATE TABLE声明必须指定三个关键的事情:
- 要创建的表的名称。
- 表结构,例如:列名和对应的数据类型。
- 表引擎及其设置,这决定了对此表的查询操作是如何在物理层面执行的所有细节。
表字段类型:
- 整数: UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256
- 浮点: Float32, Float64 和 Decimal
- 布尔值: Bool
- 字符串: String, FixedString
- 日期: Date, Date32 日期, DateTime,DateTime64 日期时间
- JSON: JSON文档
- UUID: 通用唯一标识符
- 低基数型(少量枚举): LowCardinality
- 数组: Arrays
- 映射: Maps
- 聚合函数: Aggregation function
- 嵌套: Nested
- 元组: Tuples
- 可为空: Nullable
- IP地址: IPv4, IPv6
- 地理: Geo
- 特殊数据类型: 包含 表达式(Expression), 集合(Set), 无(Nothing) 和 间隔(Interval)
Maps
- 函数 mapKeys
获取所有 Map 的 Keys
- 函数 mapValues
获取所有 Map 的 Values
- 函数 mapContains
判断是否包含了某个 Key
Nested
部分函数同array
SELECT
*
FROM
test
WHERE
arrayFilter(x -> x LIKE '%title%', items.productName) != []
SELECT
*
FROM
test
WHERE
arrayFilter(x, y->(x='name1' AND y='val1'), params.name, params.val) != []
Arrays 类型相关函数
Array,借助其和相关arrayJoin()、indexof()等函数,可以完成很多关系型数据库无法高效实现的关联查询和统计。
- 函数arrayJoin(arr)
与其他函数最大的不同就是,它可以将单行数据展开到多行(普通函数不改变行数,聚合函数将多行压缩到一行),展开规则也很简单:基于参数列的数组的元素数量,展开相同数量的行,其他列的值会被简单复制。
- 函数indexOf(arr, x)
返回x元素在数组中的位置,注意序号是从1开始,0代表元素不存在。
- 函数arrayMap(func,arr1,...)
SELECT arrayMap(x -> (x + 2), [1, 2, 3]) as res;
┌─res─────┐
│ [3,4,5] │
└─────────┘
SELECT arrayMap((x, y) -> (x, y), [1, 2, 3], [4, 5, 6]) AS res
┌─res─────────────────┐
│ [(1,4),(2,5),(3,6)] │
└─────────────────────┘
- 函数arrayFilter(func, arr1, …)
SELECT arrayFilter(x -> x LIKE '%World%', ['Hello', 'abc World']) AS res
┌─res───────────┐
│ ['abc World'] │
└───────────────┘
SELECT
arrayFilter(
(i, x) -> x LIKE '%World%',
arrayEnumerate(arr),
['Hello', 'abc World'] AS arr)
AS res
┌─res─┐
│ [2] │
└─────┘
- 函数arrayMin,arrayMax,arraySum,arrayAvg([func,] arr)
数组计算
- 函数arrayCumSum([func,] arr1, …), arrayCumSumNonNegative(arr)
均为累加求和函数
- 函数arrayProduct(arr)
将数据元素相乘
- 函数arrayCompact(arr)
从数组中删除连续的重复元素。结果值的顺序由源数组中的顺序决定。
- 函数arrayZip(arr)
合并多个数组,合并后长度不变,元素变为多个数组相同位置元素组成的元组(tuples)
- 函数empty(arr), notEmpty(arr)
判断数组是否为空
- 函数length(arr)
返回数组长度
- 函数range(end),range([start,]end[,step])
返回一个由UInt数字组成的数组,可以指定长度
- 函数arrayConcat(arrays)函数
将多个数组进行组合
- 函数has(arr, elem), hasAll(arr1,arr2),hasAny(arr1,arr2),hasSubstr(arr1,arr2)
检查数组中元素包含关系: has(): arr是否有特定元素 hasAll(): arr1是否有特定arr2数组 hasAny(): 是否有任意相同元素 hasSubstr(): arr1= prefix+arr2+suffix时,才为1,否则均为0。
SELECT hasAll([1.0, 2, 3, 4], [1, 3]) returns 1.
SELECT hasAll(['a', 'b'], ['a']) returns 1.
SELECT hasAny([[1, 2], [3, 4]], [[1, 2], [1, 3]]) returns 1.
SELECT hasAll([[1, 2], [3, 4]], [[1, 2], [1, 3]]) returns 0.
SELECT hasSubstr([1, 2, 3, 4], [2, 3]) returns 1.
SELECT hasSubstr([1, 2, 3, 4], [1, 3]) returns 0.
- 函数arrayCount([func,] arr)
统计数组中,符合func函数的数量,func可以是一个lambda表达式
- 函数countEqual(arr, x)
返回数组中x元素的数量,等同于arrayCount (elem -> elem = x, arr)
- 函数arrayEnumerate(arr)
返回array(1,2,3,...,length(arr))
该函数通常跟ARRAY JOIN关键字一起试用,在应用ARRAY JOIN后为每个数组进行计算一次
- 函数arrayEnumerateUniq(arr)
返回与源数组大小相同的数组,其中每个元素表示与其下标对应的源数组元素在源数组中出现的次数。
- 函数arrayPopBack(), arrayPopFront(), arrayPushBack(), arrayPushFront()
数据元素进出操作
- 函数arrayResize(array, size[, extender])
改变数组长度
如果size大于数组的初始大小,则使用extender值或数组项的数据类型的默认值将数组扩展到右侧,extender可以是NULL
- 函数arraySlice(array, offset[, length])
返回一个子数组,包含从指定位置的指定长度的元素。
- 函数arraySort([func,] arr, …),arrayReverseSort([func,] arr, …)
对arr数组的元素进行排序。如果指定了func函数,则排序顺序由func函数的调用结果决定。如果func接受多个参数,那么arraySort函数也将解析与func函数参数相同数量的数组参数。func支持lambda表达式
- 函数arrayDifference(arr)
返回一个数组,其中包含所有相邻元素对之间的差值。
- 函数arrayUniq(arr)
如果传递一个参数,则计算数组中不同元素的数量。
如果传递了多个参数,则它计算多个数组中相应位置的不同元素元组的数量。
- 函数arrayDistinct(arr)
返回一个包含所有数组中不同元素的数组。
- 函数arrayReduce(agg_func,arr1)
将聚合函数应用于数组并返回其结果。如果聚合函数具有多个参数,则此函数可应用于相同大小的多个数组。
- 函数arrayEnumerateDense(arr)
返回与源数组大小相同的数组,指示每个元素首次出现在源数组中的位置。例如:arrayEnumerateDense([10,20,10,30])= [1,2,1,3]。
- 函数arrayIntersect(arr)
返回所有数组元素的交集
- 函数arrayReverse(arr)
反转函数元素
数据库引擎
- Atomic - 默认的,就用这个
- MySQL - 连接MySQL
- PostgreSQL - 连接PostgreSQL
- SQLite - 连接SQLite
- Lazy - 优化 *Log 表
- MaterializedMySQL
- MaterializedPostgreSQL
- Replicated
❗❗❗ 表引擎 ❗❗❗ 表引擎决定:
- 数据如何存储,写到哪儿,从哪儿读。
- 支持哪些查询,如何查询。
- 并发数据访问。
- 使用索引,如果需要的话
- 是否可以执行多线程请求。
- 数据复制参数。
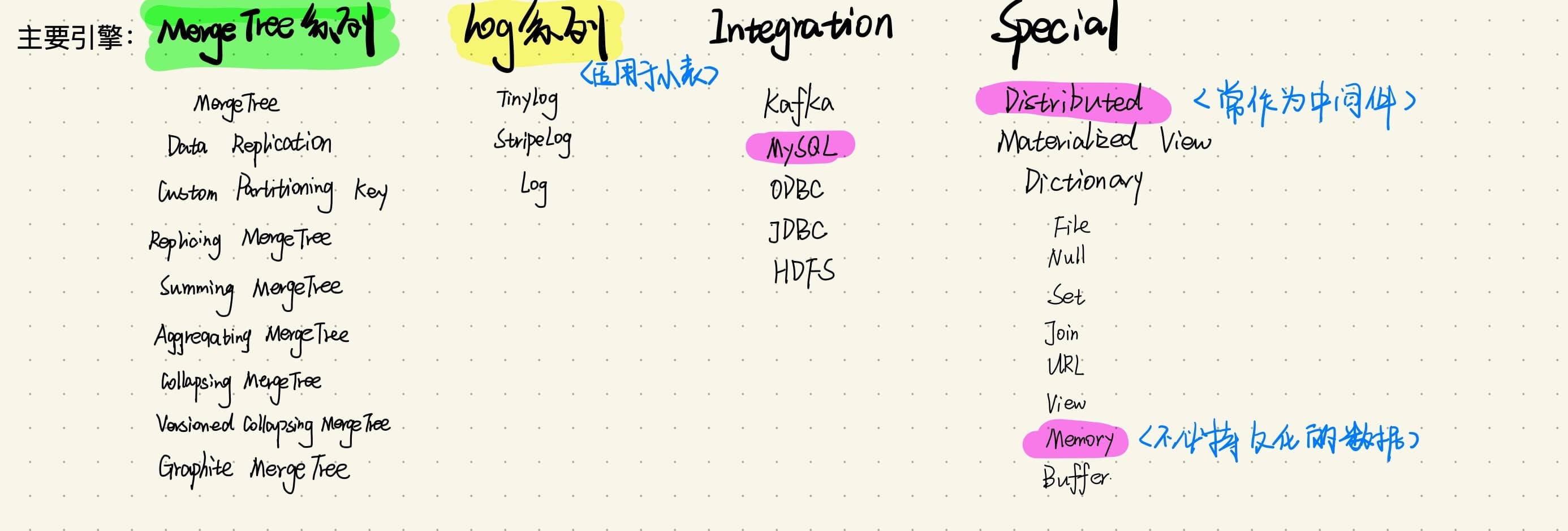
- MergeTree系列引擎
该系列引擎是执行高负载任务的最通用和最强大的表引擎,它们的特点是可以快速插入数据以及进行后续的数据处理。该系列引擎还同时支持数据复制(使用Replicated的引擎版本),分区 (partition) 以及一些其它引擎不支持的额外功能。
- MergeTree (合并)
- ReplacingMergeTree (合并去重)
- SummingMergeTree (合并数据)
- AggregatingMergeTree (聚合计算)
- CollapsingMergeTree (折叠合并删除数据)
- VersionedCollapsingMergeTree (多线程合并删除数据)
- GraphiteMergeTree
- Log系列引擎
该系列引擎是具有最小功能的轻量级引擎。当你需要快速写入许多小表(最多约有100万行)并在后续任务中整体读取它们时使用该系列引擎是最有效的。
- TinyLog
- StripeLog
- Log
- Integration 引擎
该系列引擎是与其它数据存储以及处理系统集成的引擎,如 Kafka,MySQL 以及 HDFS 等,使用该系列引擎可以直接与其它系统进行交互,但也会有一定的限制,如确有需要,可以尝试一下。
- ODBC
- JDBC
- MySQL
- MongoDB
- ...
- Special引擎
该系列引擎主要用于一些特定的功能,如 Distributed 用于分布式查询,MaterializedView 用来聚合数据,以及 Dictionary 用来查询字典数据等。
Distributed
MaterializedView
Dictionary
Merge
Memory
Set
...
编辑数据
-- 单行数据插入,仅作为演示用,生产推荐批量.
INSERT INTO default.book(name, publisher, publisherNo, price, publicationDate, isbn) VALUES('姓名2', '出版商2', '出版商编号2', '10000', '2023-05-09', 'isbn0119'),('姓名2', '出版商2', '出版商编号2', '10000', '2023-05-09', 'isbn0120');
-- 修改数据,作为key的行不能修改
-- ALTER TABLE default.book UPDATE isbn='isbn0102' WHERE publisher='出版商2'; # 该行报错,键不能修改
ALTER TABLE default.book UPDATE publisher='出版商2' WHERE isbn='isbn0102';
-- 删除数据
ALTER TABLE default.book DELETE WHERE isbn='isbn0102';
-- 手动合并分区
OPTIMIZE TABLE test_merge_tree FINAL;
官网示例
INSERT INTO uk_price_paid
WITH
splitByChar(' ', postcode) AS p
SELECT
toUInt32(price_string) AS price,
parseDateTimeBestEffortUS(time) AS date,
p[1] AS postcode1,
p[2] AS postcode2,
transform(a, ['T', 'S', 'D', 'F', 'O'], ['terraced', 'semi-detached', 'detached', 'flat', 'other']) AS type,
b = 'Y' AS is_new,
transform(c, ['F', 'L', 'U'], ['freehold', 'leasehold', 'unknown']) AS duration,
addr1,
addr2,
street,
locality,
town,
district,
county
FROM url(
'http://prod.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com/pp-complete.csv',
'CSV',
'uuid_string String,
price_string String,
time String,
postcode String,
a String,
b String,
c String,
addr1 String,
addr2 String,
street String,
locality String,
town String,
district String,
county String,
d String,
e String'
) SETTINGS max_http_get_redirects=10;
英国房地产支付价格(4.5GB, 28205961行) 数据下载较慢
一些查询
查询 1. 每年平均价格
SELECT
toYear(date) AS year
, ROUND(AVG(price)) AS price
, bar(price, 0, 1000000, 80)
FROM
uk_price_paid
GROUP BY
year
ORDER BY
year
查询 2. 伦敦每年的平均价格
SELECT
toYear(date) AS year
, ROUND(AVG(price)) AS price
, bar(price, 0, 2000000, 100)
FROM
uk_price_paid
WHERE
town = 'LONDON'
GROUP BY
year
ORDER BY
year
查询 3. 最昂贵的社区
SELECT
town
, district
, COUNT() AS c
, ROUND(AVG(price)) AS price
, bar(price, 0, 5000000, 100)
FROM
uk_price_paid
WHERE
date >= '2020-01-01'
GROUP BY
town,
district
HAVING
c >= 100
ORDER BY
price DESC
LIMIT 100
查询 4. 统计数量,空间大小
SELECT count() FROM uk_price_paid
SELECT formatReadableSize(total_bytes) FROM system.tables WHERE name = 'uk_price_paid'
Projection
有点类似于MySQL的索引
ALTER TABLE uk_price_paid
ADD PROJECTION projection_by_year_district_town
(
SELECT
toYear(date),
district,
town,
avg(price),
sum(price),
count()
GROUP BY
toYear(date),
district,
town
)
使老数据生效
ALTER TABLE uk_price_paid
MATERIALIZE PROJECTION projection_by_year_district_town
SETTINGS mutations_sync = 1
对比查询,查询效果相当有效.至少提升10倍速度
# 查询平均价格
29 rows in set. Elapsed: 0.091 sec. Processed 28.21 million rows, 169.24 MB (311.25 million rows/s., 1.87 GB/s.)
29 rows in set. Elapsed: 0.005 sec. Processed 79.50 thousand rows, 2.07 MB (14.87 million rows/s., 386.74 MB/s.)
# 查询伦敦平均价格
29 rows in set. Elapsed: 0.019 sec. Processed 28.21 million rows, 83.19 MB (1.47 billion rows/s., 4.32 GB/s.)
29 rows in set. Elapsed: 0.006 sec. Processed 79.50 thousand rows, 2.27 MB (13.07 million rows/s., 372.94 MB/s.)
# 查询前100的价格
100 rows in set. Elapsed: 0.066 sec. Processed 28.21 million rows, 299.65 MB (430.43 million rows/s., 4.57 GB/s.)
100 rows in set. Elapsed: 0.006 sec. Processed 13.97 thousand rows, 673.13 KB (2.30 million rows/s., 110.96 MB/s.)
单机部署
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑ 不做任何配置就是单机模式
集群部署
- 在群集的所有机器上安装ClickHouse服务端
- 在配置文件中设置集群配置,主要包含clickhouse服务和zookeeper服务
- 在每个实例上创建本地表
- 创建一个分布式表
分布式表实际上是一种view,映射到ClickHouse集群的本地表。 从分布式表中执行SELECT查询会使用集群所有分片的资源。 您可以为多个集群指定configs,并创建多个分布式表,为不同的集群提供视图。
分布式知识点
注意项
- 主键可以重复
- 列指定了键的数据不可被修改
- SQL中,字段区分大小写,关键字不区分大小写
- SQL中,字符支持单引号,不支持双引号